提交您的產(chǎn)品
提交您的產(chǎn)品  Ai應(yīng)用
Ai應(yīng)用 Ai資訊
Ai資訊 AI生圖
AI生圖 AI生視頻
AI生視頻 開源AI應(yīng)用平臺
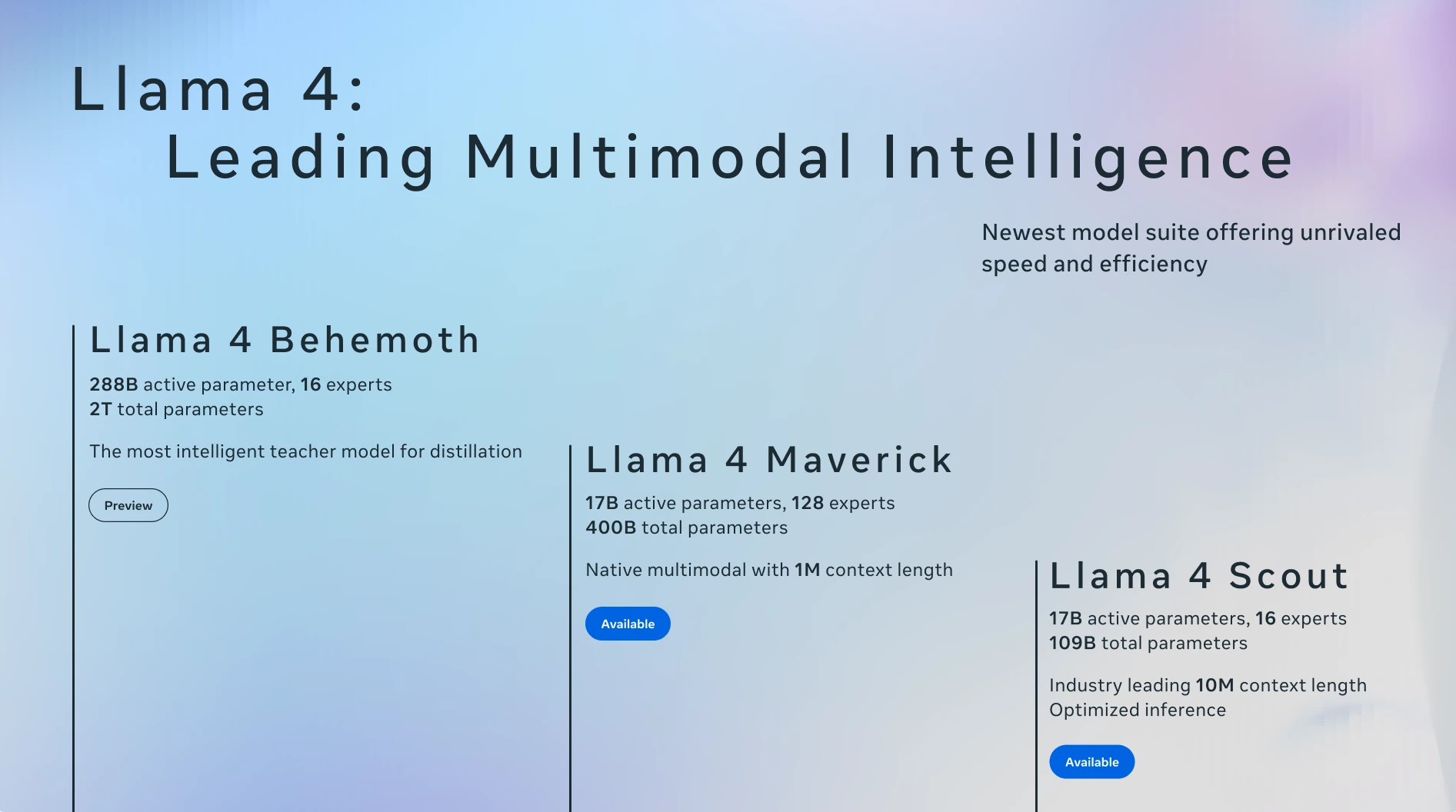
開源AI應(yīng)用平臺Llama 4 Scout和Maverick有什么區(qū)別?

2025 年 4 月 5 日,Meta 發(fā)布了最新一代開源ai模型Llama 4,其中包括 Llama 4 Scout 和 Llama 4 Maverick。這兩款A(yù)I模型都是首批采用混合專家(MoE)架構(gòu)的多模態(tài)模型,他們有什么區(qū)別呢?
Llama 4 Scout 和 Llama 4 Maverick 的主要區(qū)別:
Llama 4 Scout
參數(shù)規(guī)模:170 億個活躍參數(shù),16 個“專家”模型,總參數(shù)量為 1090 億。
上下文窗口:支持高達(dá) 1000 萬個 token 的上下文窗口,這使得它在處理冗長文檔時表現(xiàn)尤為優(yōu)異。
應(yīng)用場景:擅長文檔摘要和基于大型代碼庫的推理,適合需要高效推理和長文本處理的場景。
硬件需求:可以在單個 NVIDIA H100 GPU 上運行,通過 Int4 量化后,資源需求較低。

Llama 4 Maverick
參數(shù)規(guī)模:170 億個活躍參數(shù),128 個“專家”模型,總參數(shù)量高達(dá) 4000 億。
上下文窗口:支持 100 萬個 token 的上下文窗口。
應(yīng)用場景:在創(chuàng)意寫作、代碼生成、翻譯、推理、長文本上下文總結(jié)和圖像基準(zhǔn)測試中表現(xiàn)超過了 OpenAI 的 GPT-4o 和谷歌的 Gemini 2.0 等模型。
硬件需求:需要在 NVIDIA H100 DGX 主機(jī)或同等性能的設(shè)備上運行。

兩者比較
性能:Maverick 在多模態(tài)任務(wù)和推理能力上表現(xiàn)更強(qiáng),而 Scout 在長文本處理和文檔摘要方面更具優(yōu)勢。
資源需求:Scout 更適合資源受限的場景,因為它可以在單個 GPU 上運行;Maverick 則需要更高的硬件配置。
應(yīng)用場景:Scout 適用于需要處理大量文本的場景,如文檔處理和代碼推理;Maverick 更適合需要多模態(tài)交互和復(fù)雜推理的任務(wù),如創(chuàng)意寫作和圖像處理。
推理成本
Llama 4 Scout:由于其較小的模型規(guī)模和高效的量化技術(shù),推理成本相對較低,適合需要快速響應(yīng)和低資源消耗的應(yīng)用。
Llama 4 Maverick:雖然其總參數(shù)量更大,但由于采用了混合專家架構(gòu),其推理成本也得到了優(yōu)化。Meta 估計,Llama 4 Maverick 的推理成本為每 100 萬個 tokens 0.19 美元至 0.49 美元(輸入和輸出比例為 3:1),這使得它比像 GPT-4o 這樣的專有模型便宜得多。
Llama 4 Scout 更適合需要處理長文本和資源受限的場景,而 Llama 4 Maverick 則在推理和代碼生成能力上表現(xiàn)出色,適合需要高性能和多模態(tài)處理的應(yīng)用。兩者都通過混合專家架構(gòu)實現(xiàn)了高效的資源利用,但具體的資源需求和成本取決于你自身的應(yīng)用場景和硬件。