提交您的產(chǎn)品
提交您的產(chǎn)品  Ai應(yīng)用
Ai應(yīng)用 Ai資訊
Ai資訊 AI生圖
AI生圖 AI生視頻
AI生視頻 開源AI應(yīng)用平臺
開源AI應(yīng)用平臺SmolDocling:將復(fù)雜的文檔轉(zhuǎn)換為結(jié)構(gòu)化文本的輕量型視覺語言模型

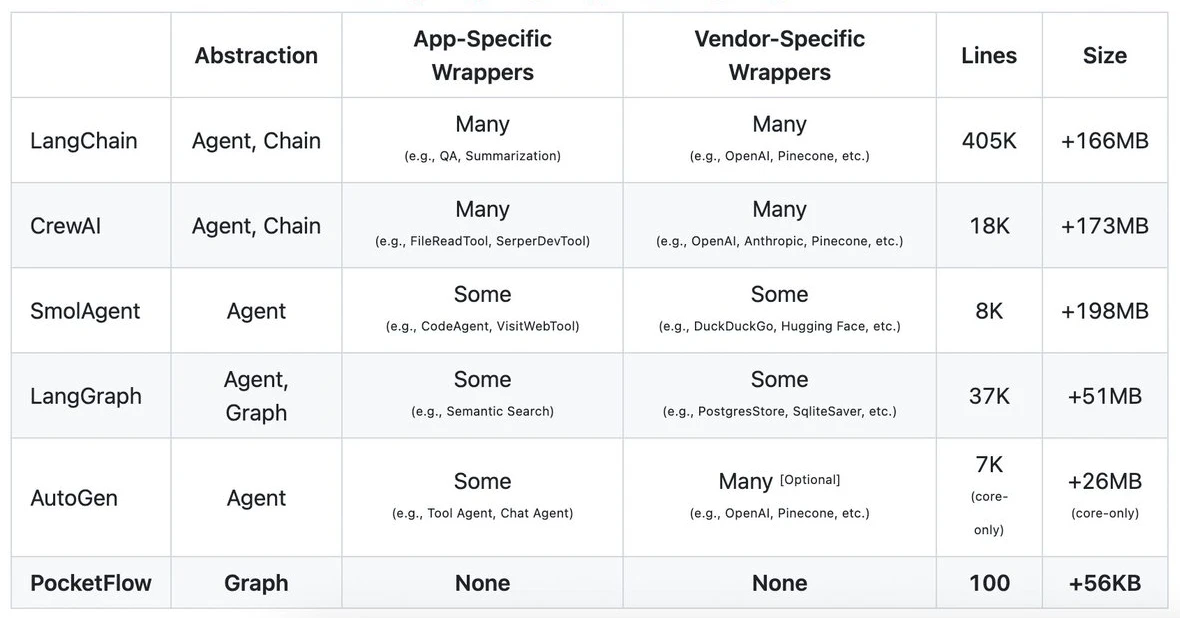
SmolDocling是什么?
SmolDocling 是由 IBM Research 和 Hugging Face 聯(lián)合開發(fā)的輕量型視覺語言模型,專為端到端多模態(tài)文檔轉(zhuǎn)換而設(shè)計。它僅包含 256M 參數(shù),能夠在消費級 GPU 上快速處理文檔,每頁文檔的處理時間僅需 0.35 秒。SmolDocling 的核心使命是將任意圖片中的復(fù)雜內(nèi)容轉(zhuǎn)化為可編輯的結(jié)構(gòu)化數(shù)據(jù)。
SmolDocling功能
DocTags 用于高效標(biāo)記:引入 DocTags,這是一種高效且簡潔的文檔表示方式,與 DoclingDocuments 完全兼容。
OCR(光學(xué)字符識別):能夠從圖像中準(zhǔn)確提取文本。
布局和定位:保留文檔結(jié)構(gòu)和文檔元素的 邊界框。
代碼識別:檢測并格式化代碼塊,包括縮進(jìn)。
公式識別:識別并處理數(shù)學(xué)表達(dá)式。
圖表識別:提取并解釋圖表數(shù)據(jù)。
表格識別:支持帶列標(biāo)題和行標(biāo)題的結(jié)構(gòu)化表格提取。
圖形分類:區(qū)分圖形和圖形元素。
標(biāo)題對應(yīng):將標(biāo)題與相關(guān)圖像和圖形鏈接起來。
列表分組:正確組織和結(jié)構(gòu)化列表元素。
全頁轉(zhuǎn)換:處理整個頁面,包括頁面上的所有元素(代碼、方程、表格、圖表等)。
OCR 帶邊界框:使用邊界框進(jìn)行 OCR 區(qū)域識別。
通用文檔處理:適用于科學(xué)和非科學(xué)文檔的訓(xùn)練。
無縫 Docling 集成:可以導(dǎo)入到 Docling 并以多種格式導(dǎo)出(如 HTML、Markdown 等)。
快速推理:在 A100 GPU 上平均每頁處理時間為 0.35 秒。
雜的圖像、PDF文檔高效轉(zhuǎn)換為結(jié)構(gòu)化文本")
模型擴(kuò)展與優(yōu)化
支持多種指令:支持多種指令,例如將頁面轉(zhuǎn)換為 DocTags、將圖表轉(zhuǎn)換為表格、將公式轉(zhuǎn)換為 LaTeX 等。
多語言支持:雖然主要支持英語,但可能通過擴(kuò)展支持更多語言。
持續(xù)改進(jìn):改進(jìn)圖表識別、支持多頁推理、化學(xué)識別等功能。
SmolDocling應(yīng)用場景
學(xué)術(shù)研究:快速將學(xué)術(shù)論文和研究報告轉(zhuǎn)換為結(jié)構(gòu)化格式,便于提取關(guān)鍵信息。
商業(yè)文檔處理:自動轉(zhuǎn)換商業(yè)合同、報告和表格,便于企業(yè)進(jìn)行文檔存儲、檢索和分析。
技術(shù)文檔管理:將技術(shù)手冊、代碼文檔等轉(zhuǎn)換為可編輯格式,支持代碼片段的準(zhǔn)確識別和格式化。
教育領(lǐng)域:將教材、講義中的內(nèi)容(如公式、圖表)提取并轉(zhuǎn)換為易于理解的格式。
醫(yī)療文檔處理:處理醫(yī)療報告和研究論文,提取關(guān)鍵信息,輔助醫(yī)療決策。
移動與低資源設(shè)備支持:可在移動設(shè)備或資源受限的環(huán)境中運行。
SmolDocling使用方法
模型下載:可以從 Hugging Face 模型庫下載 SmolDocling。
本地部署:由于其體積小,可在普通筆記本電腦或移動設(shè)備上運行。
API 調(diào)用:可以通過 Hugging Face 提供的 API 接口調(diào)用 SmolDocling。
微調(diào)模型:開發(fā)者可以通過微調(diào)模型適配特定場景,如醫(yī)療報告解析、財務(wù)表格識別。
Hugging Face 模型庫:https://huggingface.co/ds4sd/SmolDocling-256M-preview
DEMO:https://huggingface.co/spaces/ds4sd/SmolDocling-256M-Demo