提交您的產品
提交您的產品  Ai應用
Ai應用 Ai資訊
Ai資訊 AI生圖
AI生圖 AI生視頻
AI生視頻 開源AI應用平臺
開源AI應用平臺OmniGen2:開源版的Flux.1 Kontext

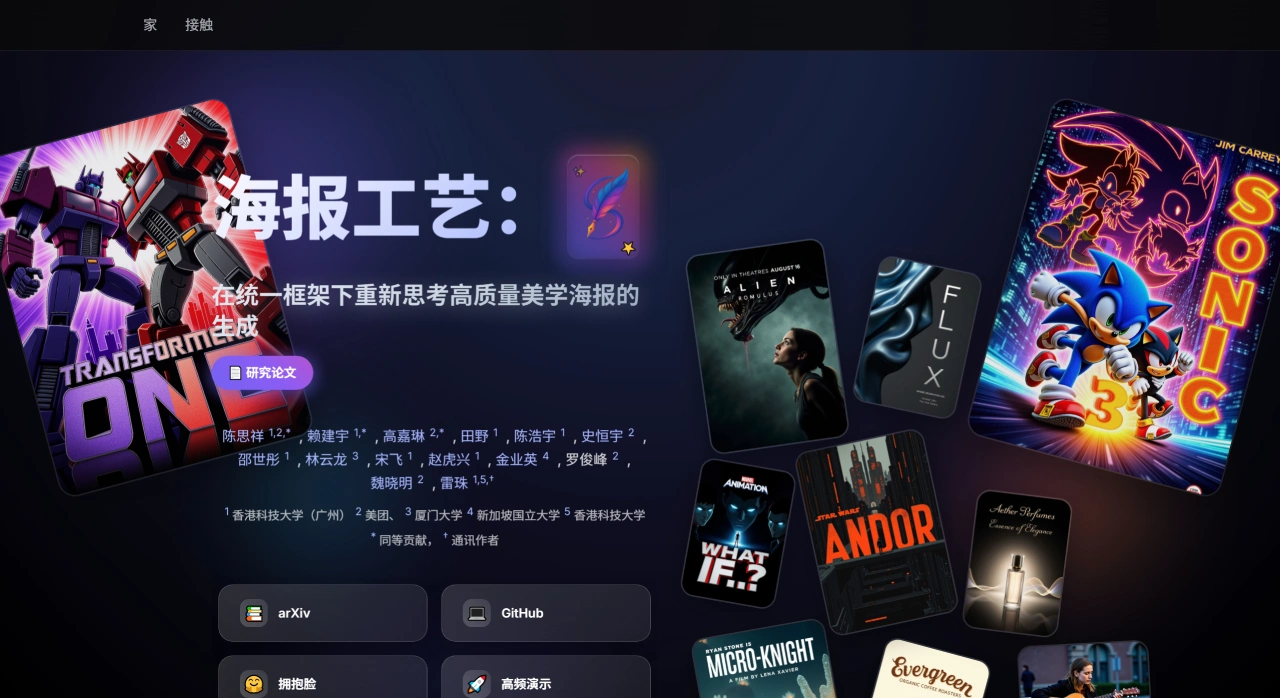
OmniGen2 是智源研究院推出的多模態生成模型。和Flux.1 Kontext類似,能通過文字修改圖片,它把視覺理解、文本轉圖像合成、基于指令的圖像編輯,以及主題驅動的上下文生成集成到同一個框架里。這個模型采用解耦架構,在保留語言建模能力的同時,能輸出細節細膩且風格統一的視覺效果。另外,它還引入了多模態反思機制,可以對生成結果進行分析、審視并迭代優化,將推理和自我修正融入圖像生成過程,讓它在生成和理解任務上都有出色表現,成為輕量級開源模型的新標桿。

核心功能
文本轉圖像生成:用戶能根據文本描述生成各種場景和角色的圖像,比如 “戴皇冠的貓躺在天鵝絨王座上”“黑暗巫師在古老洞穴里施展魔法” 這類描述。
圖像編輯功能:支持對生成的圖像進行多種修改,像改變服裝顏色、更換背景,或是添加、刪除畫面元素等操作。
風格轉換:可以把圖像轉換成不同的藝術風格,比如動漫風、油畫風都能實現。
角色和場景合成:能把不同圖像里的角色或元素組合到新場景中,例如 “讓第一張圖的女孩和第二張圖的男孩在教堂舉行婚禮”。
特點
高質量輸出:生成的圖像細節豐富,視覺效果出眾。
靈活的編輯能力:提供多種編輯選項,用戶能根據需求定制圖像。
開源特性:作為開源項目,為開發者和研究者提供了更多探索開發的可能。
使用場景
創意設計:設計師可以借助 OmniGen2 快速生成設計概念和草圖。
內容創作:內容創作者能生成各種場景和角色的圖像,用于故事創作、視頻制作等場景。
教育與研究:教育工作者和研究人員可以把它作為教學和研究工具,探索多模態生成技術的應用。
應用例子
圖像生成:通過文本描述生成各類場景和角色的圖像,比如 “戴皇冠的貓躺在天鵝絨王座上”。
圖像編輯:對生成的圖像進行修改,例如改變服裝顏色、更換背景等操作。
圖像合成:將不同圖像的元素組合到新場景中,比如 “讓第一張圖的女孩和第二張圖的男孩在教堂結婚”。

關鍵問題
1. OmniGen2 的核心創新點是什么?
OmniGen2 的核心創新在于采用雙路徑解耦架構整合多模態生成能力,引入多模態反思機制實現輸出的自我優化,同時設計 Omni-RoPE 位置嵌入來提升圖像編輯和上下文生成的一致性,這些創新讓它在輕量級開源模型中樹立了新基準。
2. OmniGen2 在圖像編輯方面能實現哪些具體操作?
OmniGen2 在圖像編輯上能完成多種精細操作,包括對象處理(比如添加或移除對象,像給人物加漁夫帽、去掉畫面里的貓)、風格變換(比如把背景改成教室場景、將風格轉為吉卜力工作室風格)、顏色調整(比如把裙子顏色改成藍色)、表情修改(比如讓人物露出微笑)、動作編輯(比如讓人物舉起手)等,同時還能保持未編輯區域的視覺真實感和一致性。
3. 多模態反思機制如何提升 OmniGen2 的生成質量?
多模態反思機制讓 OmniGen2 能夠評估自己的輸出結果,識別出描述與圖像內容不符的情況(比如 “三個披薩” 但圖像里只有一個時會提示添加)、顏色或位置錯誤(比如黃色西蘭花生成成綠色時會提示改色,狗出現在椅子上而不是黃色餐桌上時會提示調整位置)等問題,并通過迭代優化生成更符合要求的結果,從而增強了輸出的可控性、可靠性和質量。
項目主頁:https://vectorspacelab.github.io/OmniGen2/
技術論文:https://github.com/VectorSpaceLab/OmniGen2
在線試用:https://huggingface.co/OmniGen2/OmniGen2
注:Flux.1 Kontext是德國黑森林實驗室(Black Forest Labs)開發的圖像生成與編輯工具。它可以根據文本和圖像提示生成和編輯圖像,包括修改對象、轉換風格、替換背景、保持角色一致性和編輯文本等。和傳統文本到圖像模型不一樣,它支持上下文圖像生成,能同時結合文本和圖像提示,直接提取和修改視覺概念,生成新的連貫圖像。