提交您的產品
提交您的產品  Ai應用
Ai應用 Ai資訊
Ai資訊 AI生圖
AI生圖 AI生視頻
AI生視頻 開源AI應用平臺
開源AI應用平臺GPT-4.1、GPT-4.1 mini與GPT-4.1 nano的區別

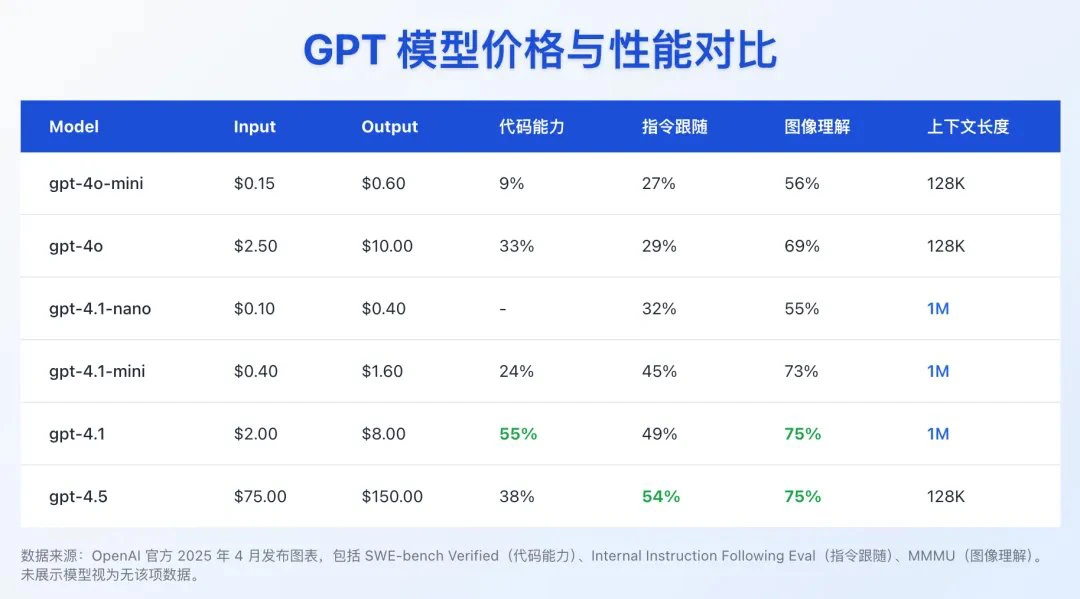
Open ai以API 的形式推出了三個新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。這些模型的性能全面超越 GPT-4o 和 GPT-4o mini,在編碼和指令跟蹤方面都有明顯提升。它們還擁有更大的上下文窗口——支持多達 100 萬個上下文標記——并且能夠通過改進的長上下文理解更好地利用這些上下文,讓我們看看它們之間有什么區別?
")
定位
GPT-4.1:作為GPT-4o的升級版,GPT-4.1在多模態能力(文本、圖像、音頻)基礎上進一步優化,響應速度更快、推理深度更強,尤其在寫作、編程和復雜問答場景中表現更自然,減少“答非所問”的情況。其上下文窗口支持1M tokens,最大輸出32,768 tokens,并計劃支持所有Copilot套餐。
GPT-4.1 mini:定位為中端輕量模型,專為邊緣設備(如手機App、小程序)和輕量任務設計,犧牲部分性能以降低資源消耗,適合實時性要求高但算力有限的場景。與GPT-4o mini類似,其參數規模較小(約8B),但保留了核心多模態功能。
GPT-4.1 nano:是極致輕量化版本,專為移動端和嵌入式AI打造,參數規模更小(推測可能低于mini版本),強調低延遲和離線運行能力,例如在舊手機或無網絡環境下仍可使用基礎AI功能。
")
1. 模型大小與參數
GPT-4.1:完整的大型模型,擁有最多的參數,適合復雜任務和需要強大計算能力的場景。
GPT-4.1 mini:中等大小的模型,參數量較少,適合在資源受限的環境中使用,如普通的個人電腦或服務器。
GPT-4.1 nano:最小的模型,參數量最少,主要針對移動端和嵌入式設備等資源極其受限的場景。
2. 性能與效率
GPT-4.1:
在編碼、指令遵循和長文本理解等任務上表現出色。
在 SWE-bench Verified 編碼基準測試中得分為 54.6%,比 GPT-4o 提高了 21.4%。
在 Video-MME 長文本理解基準測試中得分為 72.0%,比 GPT-4o 提高了 6.7%。
GPT-4.1 mini:
在許多基準測試中表現接近甚至超過 GPT-4o,延遲降低了近一半,成本降低了 83%。
在 MMMU 圖像理解基準測試中表現優異。
GPT-4.1 nano:
是最快的模型,延遲極低,通常在 128,000 輸入 token 的查詢中,首次返回 token 的時間不到五秒。
在 MMLU、GPQA 和 Aider polyglot coding 等任務上的表現甚至超過了 GPT-4o mini。
3. 適用場景
GPT-4.1:適用于需要強大計算能力和復雜任務處理的場景,如專業的軟件開發、復雜的法律文檔分析、大規模的數據處理等。
GPT-4.1 mini:適合在中端設備上運行,如普通的個人電腦、小型服務器等,可以處理一些中等復雜度的任務,如日常的文本生成、簡單的編程輔助、圖像理解等。
GPT-4.1 nano:主要針對移動端和嵌入式設備,如智能手機、平板電腦、智能家居設備等,適用于對響應速度要求高且資源受限的場景,如快速的文本分類、自動補全等。
4. 成本
| 模型 | 輸入(每百萬 token) | 緩存輸入(每百萬 token) | 輸出(每百萬 token) | 混合定價\*(每百萬 token) |
|---|---|---|---|---|
| GPT-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| GPT-4.1 mini | $0.40 | $0.10 | $1.60 | $0.42 |
| GPT-4.1 nano | $0.10 | $0.025 | $0.40 | $0.12 |
*基于典型的輸入/輸出和緩存比例。
5. 其他特點
長文本處理能力:
所有三個模型都支持 100 萬 token 的上下文窗口,比之前的 GPT-4o 模型(12.8 萬 token)大幅增加。
GPT-4.1 在長文本理解方面表現出色,能夠更好地處理復雜的多文檔任務。
指令遵循能力:
GPT-4.1 在指令遵循方面有顯著提升,特別是在復雜的多輪對話中表現更好。
圖像理解:
GPT-4.1 mini 在圖像理解方面表現突出,通常優于 GPT-4o。
官方介紹:https://openai.com/index/gpt-4-1/