提交您的產(chǎn)品
提交您的產(chǎn)品  Ai應(yīng)用
Ai應(yīng)用 Ai資訊
Ai資訊 AI生圖
AI生圖 AI生視頻
AI生視頻 開源AI應(yīng)用平臺
開源AI應(yīng)用平臺FantasyPortrait:單張靜態(tài)圖像生成多角色的情感化面部動畫

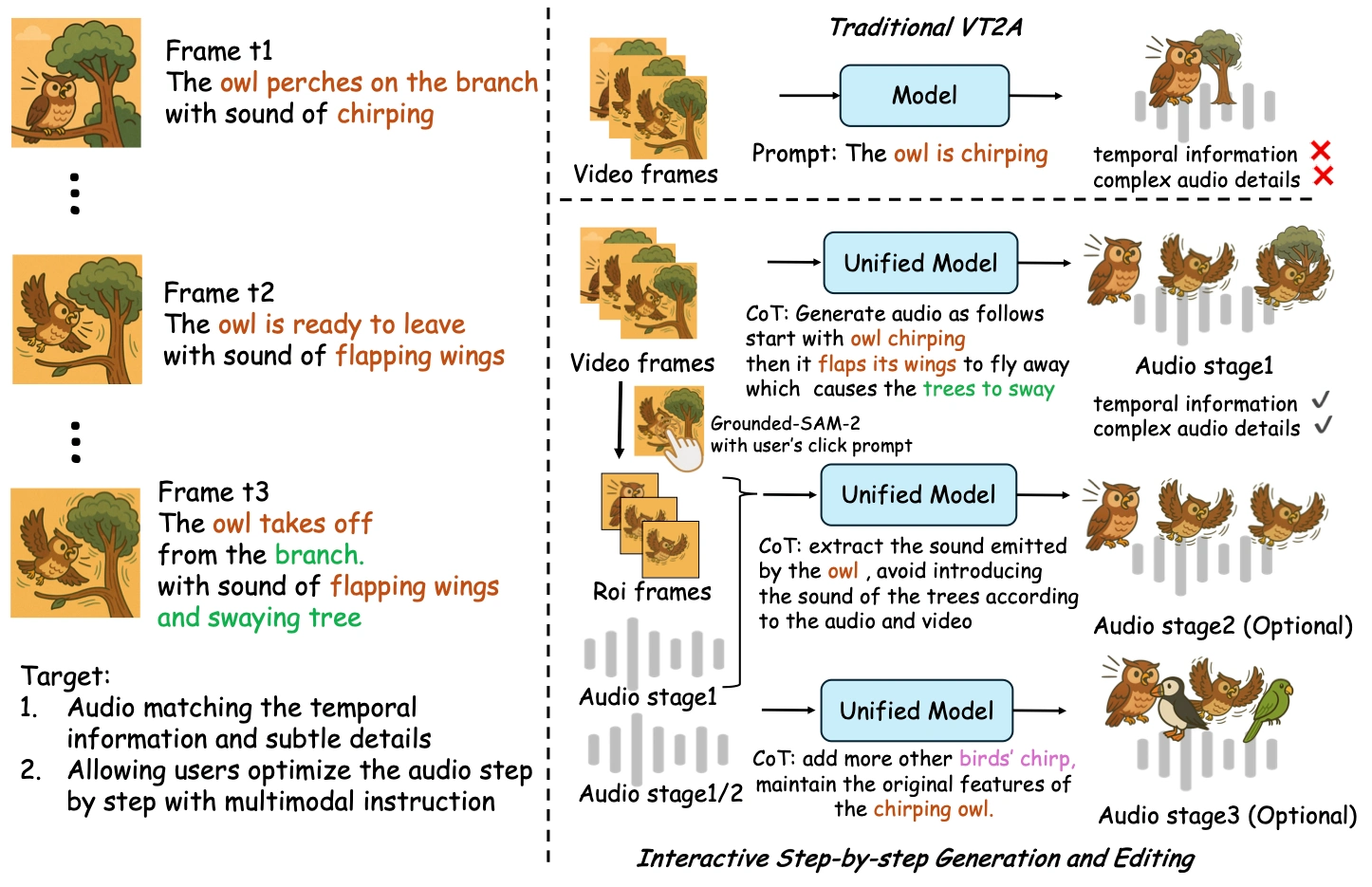
FantasyPortrait 是阿里巴巴高德地圖團(tuán)隊(duì)和北京郵電大學(xué)聯(lián)合開發(fā)的框架,可以從單張靜態(tài)圖像生成多角色的情感化面部動畫。它通過隱式特征提取復(fù)雜表情,替代傳統(tǒng)幾何先驗(yàn),提升跨身份遷移能力,并利用掩碼交叉注意力機(jī)制避免多角色間的特征干擾。此外,它還支持多風(fēng)格角色適配、零樣本動物動畫生成以及低資源音頻驅(qū)動等功能,適用于數(shù)字人、虛擬偶像、游戲 NPC 等領(lǐng)域,代碼已在 GitHub 開源。
圖像生成多角色的情感化面部動畫")
核心功能
?隱式表情增強(qiáng)學(xué)習(xí):通過隱式特征提取復(fù)雜表情,如唇部運(yùn)動和情感表達(dá),替代傳統(tǒng)顯式幾何先驗(yàn),提升跨身份遷移能力。
?掩碼交叉注意力機(jī)制:為多角色生成獨(dú)立表情控制區(qū)域,避免特征干擾,實(shí)現(xiàn)“一人一頻道”的協(xié)調(diào)動畫。
?多模態(tài)擴(kuò)展性:支持文本和音頻驅(qū)動,例如用 Whisper 編碼音頻生成口型動畫,僅需少量數(shù)據(jù)微調(diào)即可適配多語言。
?數(shù)據(jù)集與評估基準(zhǔn):構(gòu)建了 Multi-Expr 數(shù)據(jù)集(3 萬 + 高質(zhì)量多角色視頻)和 ExprBench 基準(zhǔn),推動行業(yè)標(biāo)準(zhǔn)化。
方法設(shè)計(jì)方面:
?雙階段訓(xùn)練策略:先通過 UNet 編碼表情特征,再通過擴(kuò)散變換器解碼動畫序列。
?多角色控制模塊:通過特征掩碼隔離不同角色的驅(qū)動信號,保持時間維度的一致性。
數(shù)據(jù)集與評估基準(zhǔn):
?Multi-Expr 數(shù)據(jù)集:包含超過 50 萬幀的多視角表情數(shù)據(jù),是首個多角色動畫數(shù)據(jù)集。
?ExprBench 評估基準(zhǔn):用于訓(xùn)練和評估多角色肖像動畫。
實(shí)驗(yàn)結(jié)果顯示:
?跨驅(qū)動重演任務(wù):相比 StyleHEAT、PIRender 等方法,F(xiàn)ID 指標(biāo)提升 41.7%。
?多角色動畫生成場景:用戶偏好率高達(dá) 83.5%,能準(zhǔn)確生成眼部微顫、不對稱嘴角運(yùn)動等細(xì)微表情。
應(yīng)用場景包括:
?多角色動畫:支持用多個單人視頻或單個多人視頻驅(qū)動多個角色,生成詳細(xì)表情和逼真肖像動畫。
?多樣化角色風(fēng)格:能生成動態(tài)、富有表現(xiàn)力且自然逼真的多樣化風(fēng)格動畫。
?動物動畫:雖未在動物數(shù)據(jù)集上明確訓(xùn)練,但在動物動畫任務(wù)上泛化能力強(qiáng)。
?音頻驅(qū)動肖像動畫:通過音頻編碼和基于 Transformer 的網(wǎng)絡(luò)將音頻特征映射到潛在驅(qū)動表示,實(shí)現(xiàn)音頻驅(qū)動的肖像動畫,少量訓(xùn)練樣本下即可實(shí)現(xiàn)良好音視頻對齊。
關(guān)鍵問題解答:
技術(shù)突破有哪些?
答:一是增強(qiáng)表達(dá)隱式控制,通過隱式面部表示學(xué)習(xí)細(xì)粒度表情特征,提升嘴部動作和情感表達(dá)建模能力;二是多角色掩碼交叉注意力,獨(dú)創(chuàng)掩碼式交叉注意機(jī)制,實(shí)現(xiàn)多角色獨(dú)立控制與協(xié)同生成,解決角色間特征干擾問題。
功能特點(diǎn)有哪些?
答:包括多角色同步驅(qū)動,支持用單個或多個單人視頻、一段多人視頻同步驅(qū)動多個角色;多風(fēng)格角色適配,能為不同藝術(shù)風(fēng)格角色生成動態(tài)流暢、生動自然且風(fēng)格統(tǒng)一的視頻;零樣本動物動畫,未經(jīng)專門訓(xùn)練仍有卓越生成能力;低資源音頻驅(qū)動,可擴(kuò)展為音頻驅(qū)動框架,利用 Whisper 編碼音頻,通過輕量級 Transformer 網(wǎng)絡(luò)將音頻特征映射到潛在驅(qū)動空間。
有哪些應(yīng)用價(jià)值?
答:在影視制作中,能讓獨(dú)立動畫師輕松生成群戲表演;在游戲領(lǐng)域,可使 NPC 展現(xiàn)千人千面的微表情;在虛擬直播中,能讓多角色互動更鮮活自然。
開源信息:
GitHub 倉庫:https://github.com/Fantasy-AMAP/fantasy-portrait
項(xiàng)目官網(wǎng):https://fantasy-amap.github.io/fantasy-portrait/