提交您的產(chǎn)品
提交您的產(chǎn)品  Ai應(yīng)用
Ai應(yīng)用 Ai資訊
Ai資訊 AI生圖
AI生圖 AI生視頻
AI生視頻 開源AI應(yīng)用平臺(tái)
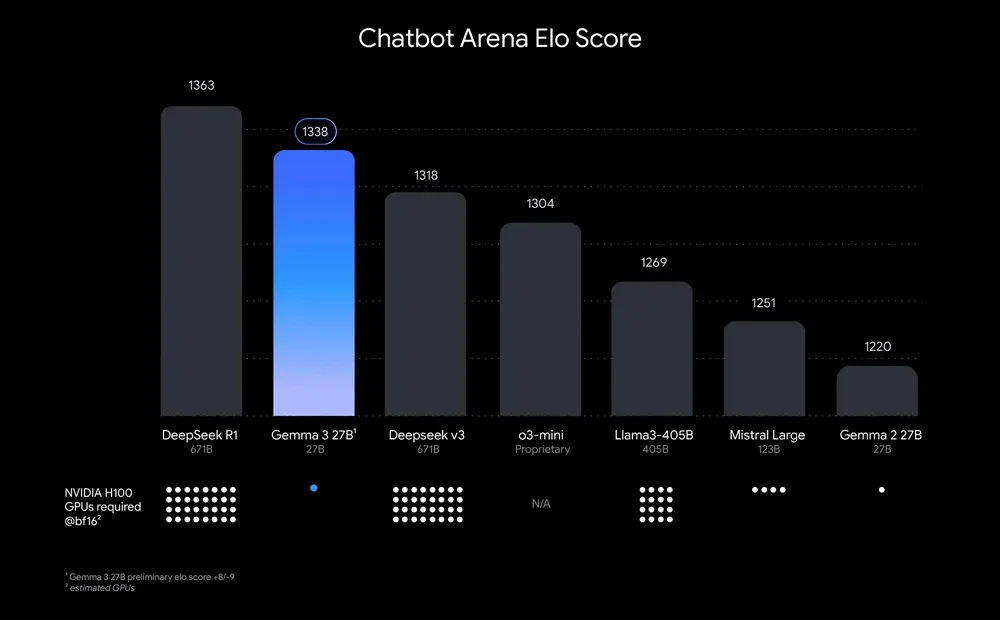
開源AI應(yīng)用平臺(tái)谷歌推出Gemma 3:性能超越DeepSeek V3、o3mini為全球第二強(qiáng)開源模型

Gemma 3是什么?
Gemma 3是Google 發(fā)布的最新開源模型,超越了 DeepSeek V3 和 o3mini,成為全球第二強(qiáng)開源模型。Gemma 3 具備強(qiáng)大的多模態(tài)能力,能夠理解文本、圖片和短視頻,同時(shí)還支持超過(guò) 140 種語(yǔ)言的預(yù)訓(xùn)練,直接支持超過(guò) 35 種語(yǔ)言。它配備了 128K 令牌的上下文窗口,能夠處理大量信息,并支持函數(shù)調(diào)用和 ai 代理開發(fā),可實(shí)現(xiàn)復(fù)雜任務(wù)的自動(dòng)化。Gemma 3 提供四種不同尺寸的模型(1B、4B、12B 和 27B),以滿足不同硬件和性能需求,并且能夠在手機(jī)、電腦等多種設(shè)備上高效運(yùn)行,支持從移動(dòng)設(shè)備到工作站的廣泛部署。
開源模型")
Gemma 3功能特征
多模態(tài)能力:支持文本、圖像和短視頻的混合輸入,能夠處理復(fù)雜的多模態(tài)任務(wù)。
強(qiáng)大的語(yǔ)言支持:預(yù)訓(xùn)練支持超過(guò) 140 種語(yǔ)言,直接支持超過(guò) 35 種語(yǔ)言。
大上下文窗口:支持 128k 令牌的上下文窗口,能夠處理大量信息,例如 30 張高分辨率圖像或 1 小時(shí)視頻。
高性能:在單 GPU 或 TPU 上的表現(xiàn)優(yōu)于其他同類模型,如 Llama、DeepSeek 和 OpenAI 的 o3-mini。
優(yōu)化與量化:提供官方量化版本,減少模型大小和計(jì)算需求,同時(shí)保持高精度。
安全性:配備 ShieldGemma 2 圖像安全分類器,可檢測(cè)和標(biāo)記危險(xiǎn)內(nèi)容。
Gemma 3 四種尺寸的模型特點(diǎn)
1B:輕量級(jí),適合在手機(jī)或筆記本等資源受限設(shè)備上運(yùn)行。
4B:適合多模態(tài)任務(wù),具備更強(qiáng)的圖像和文本處理能力。
12B:性能更強(qiáng),適合復(fù)雜圖像和視頻分析。
27B:最大版本,性能最強(qiáng),適合高性能計(jì)算場(chǎng)景。
Gemma 3應(yīng)用場(chǎng)景
圖像識(shí)別與分析:支持人臉識(shí)別、物體檢測(cè)、圖像問答和圖像比較。
視頻分析:能夠處理短視頻內(nèi)容,適用于視頻內(nèi)容分析和生成。
智能客服:結(jié)合多模態(tài)輸入,提供更智能的客戶服務(wù)。
工業(yè)質(zhì)檢:利用圖像分析能力檢測(cè)產(chǎn)品質(zhì)量問題。
代碼生成與編程輔助:支持代碼生成和自動(dòng)代碼修復(fù)。
Gemma 3使用方法
快速實(shí)驗(yàn):通過(guò) Google AI Studio 在瀏覽器中直接使用 Gemma 3,無(wú)需設(shè)置。
下載與微調(diào):從 Hugging Face、Ollama 或 Kaggle 下載模型,并使用 Hugging Face Transformers 或其他工具進(jìn)行微調(diào)。
部署選項(xiàng):支持多種部署方式,包括 Vertex AI、Cloud Run、Google GenAI API、本地環(huán)境以及 NVIDIA GPU。
開發(fā)工具支持:兼容 Hugging Face Transformers、Ollama、JAX、Keras、PyTorch 等多種開發(fā)工具。
開源模型")
Gemma 3技術(shù)
底層架構(gòu):基于與 Gemini 相同的技術(shù)架構(gòu)。
訓(xùn)練與優(yōu)化:采用知識(shí)蒸餾、強(qiáng)化學(xué)習(xí)(包括人類反饋和機(jī)器反饋)以及模型合并等技術(shù),提升性能。
視覺處理:使用動(dòng)態(tài)圖像切片技術(shù)和幀采樣與光流分析結(jié)合方案,支持高分辨率和非方形圖像。
硬件優(yōu)化:針對(duì) NVIDIA GPU 和 Google Cloud TPU 進(jìn)行深度優(yōu)化,確保高效運(yùn)行。
Gemma 3相比Gemma 2有哪些改進(jìn)?
多模態(tài)能力:新增對(duì)文本、圖像和短視頻的混合輸入支持,可處理圖像問答和視頻分析等復(fù)雜任務(wù)。
性能提升:?jiǎn)?GPU 性能更強(qiáng),推理速度提升 47%。
語(yǔ)言支持:支持超過(guò) 140 種語(yǔ)言的預(yù)訓(xùn)練,直接支持 35 種語(yǔ)言,語(yǔ)言處理能力增強(qiáng)。
上下文窗口擴(kuò)展:支持 128k 令牌,可處理更大規(guī)模的信息。
視覺處理能力:支持高分辨率圖像和視頻解析,1 小時(shí)視頻的關(guān)鍵幀提取時(shí)間縮短至 20 秒。
安全性增強(qiáng):配備 ShieldGemma 2 圖像安全分類器,可檢測(cè)危險(xiǎn)內(nèi)容。
硬件優(yōu)化:針對(duì) GPU 和 TPU 進(jìn)行深度優(yōu)化,支持多種部署選項(xiàng)。
訓(xùn)練與微調(diào):采用強(qiáng)化學(xué)習(xí)等技術(shù),提供更靈活的微調(diào)工具。